- 환경: AWS T2.micro
- 메모리: 512MB
- 목표: 1분/5분/30분 캔들, 심볼(종목) 100개 확장 고려
- 사용자: 100명 예상
안녕하세요 오늘은 캐시를 이용해 차트 조회 속도를 높이는 과정에 대해서 설명하려합니다.
우선, 차트 조회 API가 어떻게 동작하는지 설명드리겠습니다.
차트 조회 API 동작 방식

- 그림과 같이 Consumer 모듈이 (수집 과정)
- 현재 진행중인 캔들은 Redis에 저장
- 진행이 끝난 캔들은 DB에 저장
- 이후 차트 조회 API가 호출되면
- 진행중인 캔들을 Redis에서 조회
- 마감된 캔들을 DB에서 조회
- 두 데이터를 합쳐서 -> 응답
하는 구조로 되어있습니다.
쉽게 말하면 DB 에서 마감된 캔들 데이터 + Redis 에서 현재 진행중인 캔들 데이터를 합쳐 반환하게 됩니다.
그렇다면 현재 차트 조회 API 응답 속도는 어떨까요?
현재 응답 속도

1분봉 120개를 요청할 때의 응답속도입니다.
Postman 을 통해 요청을 보내봤는데 2.8초...진짜 너무 느립니다.
이 속도로 차트를 실시간으로 보기에는 무리가 있다고 판단했습니다.
왜 이렇게 느릴까요??
응답이 느린 이유를 한 번 분석해봤습니다.
문제점 분석
이유는 바로, 매 요청마다 DB를 조회하기 때문입니다.
왜 매 요청마다 DB를 조회하는 것이 느릴까요?

모든 부분이 다 Latency 이긴 하지만, 저 빨간색 네모 부분이 가장 지연이 많이 발생하는 구간입니다. 바로 3~7번 네트워크 I/O 구간입니다. 해당 부분으로 인해 매 요청마다 DB 조회하는 로직에 지연이 생깁니다.
참고 사항
참고로 현재 DB에서 쿼리를 실행하는 시간은 1ms도 걸리지 않습니다.
차트 저장 과정에서 (symbolid, bucketTime)에 유니크 인덱스를 걸어주었기 때문입니다.(중복 저장 방지를 위한 제약조건)
[인덱스 적용 후]

현재 차트 조회 실행계획을 보게 되면, Index Scan을 통해 쿼리가 실행되고 있는 것을 알 수 있습니다.
실행 시간은 1ms도 걸리지 않죠.
[인덱스 적용 전]

반면에 인덱스 적용 전에는 Seq Scan을 통해 쿼리가 실행되었고, 실행 시간은 7.6ms 정도 걸렸습니다.
(PostgreSQL Seq Scan == MySQL Full Scan)
(저장 데이터 800개 기준입니다.)
저는 이러한 데이터 지연 문제를 해결하기 위해 데이터 저장 구조를 분석하여 캐시를 적용했습니다.
차트 데이터 저장 구조 분석과 캐시 적용
## 차트 저장 구조에 따른 조회 전략과 TTL 전략 ##
Consumer 모듈이 Tick 데이터를 Consume 하여 저장하는 방식은 다음과 같습니다.
- 현재 진행중인 캔들은 Redis에 저장
- 진행이 끝난 캔들은 DB에 저장
데이터 저장 구조가 깔끔했기 때문에 캐시를 적용하여 조회하는 전략은 간단했습니다.
Closed Candles 을 캐싱해두고, 여기에 Current Candle 을 합쳐 반환하고자 했습니다. (마감된 캔들을 조회하는 과정에서 I/O 가 발생하기 때문입니다.)
다만 여기서 신경써야 할 부분은 TTL 이었습니다.
1m/5m/30m 차트가 존재했기에 다르게 TTL 을 넣어주는 것이 맞다고 생각했습니다.
그래서 [1m 차트의 경우 1분마다 봉이 마감 -> 따라서 TTL = 1분] 요런 방식으로 5m/30m 차트도 TTL 을 다르게 5분/10분으로 정해주었습니다.
결과적으로 차트당 한 번만 조회하면, 캐시 데이터를 조회할 수 있는 전략을 세웠습니다.
## 캐시 적용 ##
가장 먼저, 캐시는 L1 캐시인 Caffeine을 선택했습니다.
실시간성이 중요한 차트 서비스였기에, L2 계층인 Redis 보다 조금이라도 빠름 + 최대 종목 100개 + 차트 3개(1m/5m/30m)인 작은 서비스였기에 Caffeine 이 합리적인 선택이라고 생각했습니다. 또한, 단일 서버이기 때문에 굳이 Redis를 사용할 필요가 없었습니다.

캐시를 적용한 전체적인 흐름은 위 그림과 같았습니다.
캐시를 먼저 조회하고 캐시에 데이터가 없다면 DB를 조회하는 Cache-aside 전략을 선택했습니다. (Read-through 전략을 사용할 경우 캐시 서버가 다운되었을 때 차트 데이터를 하나도 받아올 수 없다고 생각하였습니다.)
이렇게 적용한 캐시는 API 응답을 얼마나 줄일 수 있었을까요?

엄청난 차이입니다. 캐시를 적용하고나서 281ms -> 15ms 로, 1m봉 120개 데이터 기준 약 18~19배 성능 향상을 이루어낼 수 있었습니다.
## 사용자 100명 예상 부하테스트 ##
자 이제 캐시를 적용해 성능 향상을 이끌어 냈으니, 예상 사용자 100명을 기준으로 부하 테스트를 진행해볼 차례입니다.
테스트는 100명을 기준으로 k6를 이용해 부하 테스트를 진행하였습니다.
그런데...!! 완벽할줄 알았던 캐시 적용에서 문제가 발생했습니다.
1. Thundering herd(= cache stampede) 문제 발생
(cache stampede 보다 thundering herd 가 어감이 더 좋아서 이렇게 명시하겠습니다 ㅎㅎ..)

위 로그는 데이터 캐싱 이전 시점에서 Cache Miss 가 발생한 로그입니다.
M1(=1분봉) 데이터를 올바르게 요청하였지만, 캐시가 존재하지 않는 순간에 요청이 몰리며 Cache Miss 가 발생하였습니다.
해당 로그로 파악할 수 있는 문제점은, 캐시를 도입했더라도 Cache Miss 상황에서는 DB에 부하가 집중될 수 있다는 점입니다. (결국 DB 커넥션 풀이 부족해지며 서버가 다운될 수 있습니다.)
2. Cache penetration 문제 발생

두 번째 문제입니다.
존재하지 않는 심볼(9999)에 대해 요청을 보냈음에도, 처음에는 Cache Miss -> 이후 Cache Hit 흐름으로 연결되면서 존재하지 않는 데이터에 대해서도 캐시가 생성되는 문제가 발생하였습니다.
(물론 해당 데이터를 조회할 때 NOT_FOUNT_SYMBOL 예외처리되며 데이터는 조회되지 않았습니다.)
결과적으로 현재 적용한 로컬캐시(Caffeine)는 T2.micro 상황에서 Cache miss 로 인해 DB Connection Pool Timeout 발생하여 CPU 가 폭증하며 서버 다운될 수도 있고, 여전히 해결하고자 했던 latency 문제는 특정 부분에서 존재하게 됩니다. 또한 존재하지 않는 Symbol에 대해 캐싱될 수도 있습니다.
이제, 아무 생각없이 캐시를 적용하였던 순간을 반성하며 해당 문제를 해결해보겠습니다.
캐싱 이슈 해결
캐싱 이슈를 해결하기에 앞서, 현재 어떤 구조때문에 Thundering herd, Cache penetration 문제가 생기는지 분석해보겠습니다.
현재 캐싱 키 전략
현재 캐싱 키 전략은 다음과 같습니다.

1m/5m/30m 각각 분에 따라 TTL 은 알맞게 설정되며 위와 같은 형식으로 데이터가 저장됩니다.
여기서 알 수 있는 점은,
1. 캐시 데이터는 특정 분마다 새로 생성된다는 점 ( = 키 자체가 분산됨)
2. 이에 따라, 캐시 키가 동시에 만료되어서 Thundering herd 가 일어나는 것은 아니라는 점.
3. 결과적으로 첫 차트 조회 요청이 몰리는 순간을 컨트롤 해야한다는점 입니다.
결국, 캐시 값을 생성할 때 몰리는 disk i/o 요청을 제어하려면 같은 키에 대해 1명만 DB를 조회하고, 나머지는 그 결과를 기다리게 하는 방법이 필요합니다.
동시성 제어를 위해 다음과 같은 방법을 생각해봤습니다.
1. synchronized 키워드: 캐시 조회 로직 전체에 synchronized를 거는 방법이 있습니다. 하지만 이 경우 서로 다른 키의 요청끼리도 대기해야 하므로 성능이 많이 떨어진다고 생각했습니다.
2. Key별 Lock 직접 구현: Redis 기반 Named Lock 을 구현하거나, Cocurrent 자료구조를 이용해 키별 락을 관리하는 방법이 있습니다. 특별한 방법이 없다면 해당 방법이 제일 괜찮아보였습니다.
우선 저는 이미 사용 중인 Caffeine 라이브러리가 이런 동시성 제어 기능을 내장하고 있는지 분석해 보기로 했습니다.
Caffeine 분석을 통한 Thundering herd 방어
## 현재 코드가 사용하는 메서드: getIfPresent() + put() ##
가장 먼저 현재 캐시 조회 코드에 대해서 살펴봤습니다.
// CaffeineOhlcChartStore.java - 캐시 조회
CachedChart cached = cache.getIfPresent(key); // 있나 없나 확인
if (cached != null) {
return Optional.of(cached.snapshots()); // Hit > 반환
}
return Optional.empty(); // Miss → 빈 값 반환
-------------------------------------------------------------------------
// OhlcChartService.java - 비즈니스 로직
chartStore.get(symbolId, interval, candles, endExclusive)
.orElseGet(() -> loadAndCache(...)); // Miss 시 > DB 조회 후 put()
이 구조에서 getIfPresent() 는 캐시에 데이터가 있는지 읽기만 하고, 동시 접근에 대한 제어를 하지 않습니다.
따라서 50명이 동시에 요청하면, 50명 모두 getIfPresent() 에서 null을 받고 각자 loadAndCache()를 호출하여 50번의 DB 쿼리가 발생 가능합니다.
## Caffeine의 동시성 제어 메커니즘 분석 ##
그런데, Caffeine은 내부적으로 ConcurrentHashMap을 기반으로 구현되어 있습니다. 따라서 핵심은 이 Concurrent 자료구조를 이용할 수 있는 메서드가 필요했습니다.
바로 cache.get(key, mapping) 입니다.
해당 메서드는 내부적으로 ConcurrentHashMap.computeIfAbsent()와 동일한 방식으로 동작하며, 키 단위로 락을 걸어 동시 접근을 제어합니다.
구체적인 동작 과정은 다음과 같습니다.
1. 50개의 스레드가 동시에 cache.get(key, loader)를 호출합니다.
2. Caffeine 내부에서 해당 key에 대해 하나의 스레드만 락을 획득하고 loader 함수(DB 조회)를 실행합니다.
3. 나머지 49개의 스레드는 해당 key의 연산이 완료될 때까지 대기합니다.
4. 첫 번째 스레드가 DB 조회 결과를 반환하면, 대기 중이던 49개의 스레드도 DB 조회 없이 동일한 캐시 값을 반환받습니다.
결과적으로 DB에는 단 1번의 쿼리만 실행됩니다.
즉, 현재처럼 getIfPresent() + put()을 수동으로 분리하면 Caffeine은 개입할 수 없지만, get(key, mapping)으로 로딩 책임을 Caffeine에게 위임하면 내부 동시성 제어가 가능합니다.
https://github.com/ben-manes/caffeine/wiki/Population
Population
A high performance caching library for Java. Contribute to ben-manes/caffeine development by creating an account on GitHub.
github.com
Caffeine 동작 원리는 요 문서를 참고하시면 좋을 것 같습니다.
## 해결: get(key, mapping) 적용 ##
위 분석 결과를 바탕으로, 기존의 수동 Cache-Aside 패턴을 => Caffeine의 get(key, mapping) 방식으로 변경했습니다.(여전히 Cache Aside 패턴이고 조회 + 갱신을 따로 해줬던 것을 caffeine 의 메서드를 통해 한 번에 진행한 것입니다.)
AS-IS (Thundering herd 발생)
// CaffeineOhlcChartStore - 조회와 저장이 분리되어 있음
CachedChart cached = cache.getIfPresent(key); // 락 없이 조회
// ...
cache.put(key, new CachedChart(...)); // 수동 저장
// OhlcChartService - 50명이 동시에 loadAndCache()에 진입 가능
chartStore.get(...).orElseGet(() -> loadAndCache(...));
TO-BE (Thundering herd 방어)
// CaffeineOhlcChartStore - 조회와 로딩을 Caffeine에게 위임
List<OhlcCandleSnapshot> result = cache.get(key, k -> {
// Caffeine이 이 key에 대해 락을 걸고, 단 1개의 스레드만 이 로직을 실행함
return loadClosedCandles(symbolId, interval, candles, endExclusive);
});
해당 변경으로 인해 Cache-Aside의 안정성(캐시 장애 시 DB fallback 가능)은 그대로 유지하면서도, 동시 요청이 몰리는 Cache Miss 시점에서 DB 쿼리를 단 1회로 제한할 수 있게 되었습니다.
Symbol 검증을 통한 Cache penetration 방어
다음은 Cache penetration 방어 전략입니다.
Symbol 만 검증해주면 되었기에, 어렵지 않았습니다.
AS-IS(Cache Penetration 발생)
public List<OhlcCandleSnapshot> show(Long symbolId, ...) {
// symbolId 검증 없이 바로 캐시/DB 조회 > 존재하지 않는 ID도 통과
List<OhlcCandleSnapshot> closedCandles = chartStore.getOrLoad(...);
// 여기서 Symbol 검증이 발생 (이미 캐시/DB 조회 후)
return mergeRealTimeCandleIntoSnapshot(...);
}
TO-BE(Cache Penetration 방어)
public List<OhlcCandleSnapshot> show(Long symbolId, ...) {
// 존재하지 않는 Symbol은 즉시 예외 > 캐시/DB 조회 자체를 차단
Symbol symbol = symbolService.findSymbol(symbolId);
// 유효한 symbolId만 캐시/DB에 도달
List<OhlcCandleSnapshot> closedCandles = chartStore.getOrLoad(...);
...
}
해당 부분을 구현하며 어떤 방법이 가장 효과적일까 고민을 많이 했습니다.
일반적으로 알려진 Null Caching 전략이나 BloomFilter를 도입할까 하였지만 위 방법처럼 심볼 자체를 조회하는 방법이 가장 좋다고 판단하였고, 결과적으로 Cache penetration 을 방지할 수 있었습니다.
**참고**
Null Caching: 잘못된 여러 키가 들어오면 모두 캐싱하는게 비효율적 + TTL 관리 주기 복잡
Bloom Filter: 블룸필터를 적용하기에는 심볼이 너무 적었습니다.(오버엔지니어링)
테스트 결과
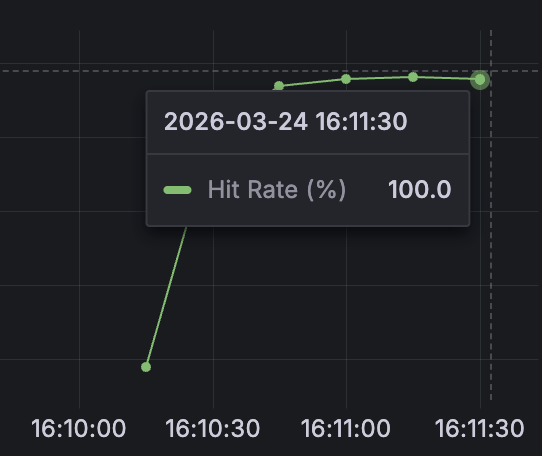
이렇게 캐싱 이슈 까지 해결해주고 부하 테스트를 진행한 결과, 캐시 히트율을 100% 달성했습니다.
(50명 기준 1분간 API 요청을 진행해주었습니다.)
Late Tick으로 인한 캐시 데이터 정합성 문제 발생
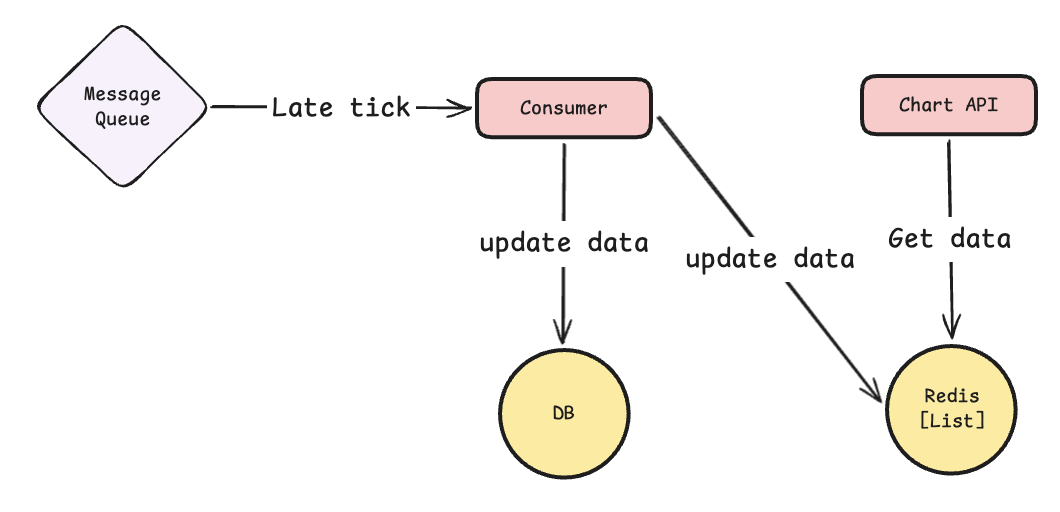
로컬 캐시(Caffeine)만으로도 상당한 성능 향상을 이루었지만, 실제 운영 환경에서는 Late Tick 으로 인한 데이터 불일치 문제가 발생함을 확인했습니다.

위 그림처럼, API 서버와 Consumer 서버가 분리되어있기 때문에, 로컬 캐시를 이용할 경우 데이터 정합성을 보장할 수 없었습니다.
이로 인해 사용자는 차트 데이터를 조회할 때마다, DB 데이터와 다른 데이터를 바라볼 수 밖에 없습니다.
캐싱 데이터 정합성 보장을 위한 해결책 - Redis Sorted Set
Late Tick 으로 인해 바뀌는 데이터에 대한 정합성을 확보하기 위해서는 글로벌 메모리 계층이 필요했습니다.
글로벌 메모리는 Redis 를 사용하기로 결정했습니다. 기존에도 Redis Stream을 메시지 브로커로 사용하여 실시간 데이터를 처리하고 있었기에, 추가적인 인프라 비용이 안들었기 때문입니다.
그리고 어떤 자료구조를 사용할지에 대해 많은 고민이 들었습니다.
후보1: Reids List
List 를 통해 저장소를 사용할 경우, Late Tick이 발생하면 과거 시점의 특정 캔들 값이 바뀌어야 하는데, List는 특정 인덱스를 찾아 수정하거나 전체를 다시 쓰고 Eviction하는 비용이 매우 컸습니다. 또한 어떤 데이터가 변경되었을 때, 해당 데이터가 List의 어디에 위치하는지 찾는 과정 자체도 O(N)으로 발생하여 비효율적이었습니다.
후보2: Reids Sorted Set - 선택!!

갑자기 머리에 번뜩이며 지나간 옵션이 있었습니다. 바로 Redis Sorted Set 입니다.
먼저, 각 캔들의 Timestamp 를 Redis Sorted Set 의 Socre로 활용할 수 있었습니다. 이를 통해 정렬 로직 없이도 시간 순서가 보장되도록 했습니다.
또한, Late Tick 이 발생하더라도 탐색 + 갱신 비용이 정말 작았습니다. Redis Sorted Set의 경우 O(log N)의 탐색비용이 들고, 과거의 13:05분 캔들을 수정해야 할 때, List처럼 전체를 뒤질 필요 없이 ZADD 명령어 하나로 해당 Timestamp의 데이터를 즉시 찾아 교체할 수 있었습니다.
마지막으로, Sorted Set 만 잘 관리하면 Cold Start도 방지할 수 있겠다는 생각이 들었습니다.
지금 프로젝트에 맞는 위와 같은 이점들이 많아서, 자료구조는 Sorted Set 으로 사용하기로 결정했습니다.
Redis Sorted Set 구현 방법

[슬라이딩 윈도우 기반 Eviction]
캔들 데이터가 무한정 늘어나는 것을 방지하기 위해 최신 1000개의 데이터만 유지하는 슬라이딩 윈도우 방식을 적용했습니다.
새로운 마감 캔들이 들어올 때마다 ZADD로 데이터를 넣고, 동시에 ZREMRANGEBYRANK key 0 -1001을 호출하여 최신 1000개의 데이터를 유지할 수 있도록 했습니다.
이로 인해 별도의 프로세스 없이도 Redis 메모리 사용량을 항상 일정하게 유지하고 + 캐싱 조회 시 일어나는 Cold Start 문제를 방지할 수 이었습니다.
[Late Tick 발생 시의 갱신 시나리오]
Late Tick으로 인해 과거 캔들이 업데이트되어야 하는 경우, Consumer 모듈은 단순히 해당 timestamp를 Score로 하여 다시 ZADD 를 해주었습니다. 해당 과정으로 인해 기존 값을 새로운 데이터로 갱신 가능하며, 복잡한 Lock 없이도 데이터 정합성을 보장했습니다.
Redis 캐싱으로 일어나는 Thundring herd
Caffeine 캐시의 get(key, loader) 기능을 통해 로컬 수준에서의 Thundering Herd는 해결했지만, Redis를 기반으로 하는 Cache-Aside 패턴으로 전환하면서 캐싱 이슈가 다시 생겼습니다.

Redis는 Caffeine과 달리 라이브러리 차원에서 애플리케이션의 로딩 책임을 제어해주지 않기 때문에 이와 같은 문제가 발생했습니다.
ReentrantLock 선택과 그 이유
현재 코인플로우는 단일 EC2 인스턴스에서 구동되는 서비스입니다. 따라서 단일 서버 내의 여러 스레드를 효율적으로 제어하는 것이 핵심이라고 생각했습니다.
그리고 이런 상황 속에서 다음과 같은 이유로 ReentrantLock을 선택하게 되었습니다.
먼저, 분산 락(Redis 기반 락)은 여러 서버 간 자원 동시성을 해결하게 해줍니다. 단일 서버 환경에서는 락 획득을 위한 외부 통신 비용이 불필요하고, 다소 과도한 설계라고 생각했습니다.
두 번째로, DB Named Lock은 락을 락 유지 동안 DB 커넥션을 지속적으로 점유하게 됩니다. 캐시 기반 구조로 DB 의존도를 줄인 상황에서, 락 관리를 위해 DB 자원을 사용하는 것은 시스템 설계 방향과 맞지 않는다고 판단했습니다.
반면 ReentrantLock은 JVM 내부에서 동작하는 로컬 락으로, 별도의 네트워크 통신 없이 메모리 수준에서 빠르게 동작하며 단일 서버 내 스레드 간 배타적 접근을 효율적으로 제어할 수 있었습니다.
ReentrantLock 작동원리와 적용
ReentrantLock은 자바에서 제공하는 Mutual Exclusion 구현체로, 다음과 같이 동작합니다.

카운트: 동일한 스레드가 락을 중복 획득한 횟수를 의미하며, 모든 획득 횟수만큼 해제(Unlock)가 이루어져야 다른 스레드가 락을 얻을 수 있습니다.
1. 재진입성 (Reentrancy): 이미 락을 획득한 스레드가 동일한 락을 다시 요청할 때 데드락에 빠지지 않고 통과할 수 있게 해줍니다.
2. 공정성 제어: 설정에 따라 가장 오래 기다린 스레드에게 락을 먼저 줄 수도 있지만, 성능을 위해 비공정 모드로 사용하여 컨텍스트 스위칭 비용을 최소화했습니다.
3. 대기 큐 관리: 락을 획득하지 못한 수집 및 조회 스레드들은 CPU를 점유하며 무한 루프를 도는 대신, 대기 상태로 들어가 시스템 자원 소모를 방어합니다.
ReentrantLock + Cache-Aside 패턴을 통한 Thundering herd 방지
최종적으로 구축한 동시성 제어 로직은 다음 그림과 같이 작동하게 됩니다. (Lock 을 획득하는 과정은 그림에 포함되어 있지 않습니다.)

public List<Candle> getChartCandles(String symbol) {
// 1. Redis 캐시 먼저 확인
List<Candle> cached = redisRepository.findAll(symbol);
if (cached != null) return cached;
// 2. 캐시 미스 시 뮤텍스 락 획득 시도
lock.lock();
try {
// 3. 락 획득 직후 다시 캐시 확인
// 대기하는 동안 앞선 스레드가 채워뒀을 수 있음
cached = redisRepository.findAll(symbol);
if (cached != null) return cached;
// 4. 단 한 명만 DB 조회 및 캐시 갱신
List<Candle> result = dbRepository.findBySymbol(symbol);
redisRepository.saveAll(symbol, result);
return result;
} finally {
lock.unlock(); // 5. 락 해제
}
}
1. 락을 획득하기 전, 먼저 Redis에 데이터가 있는지 가볍게 확인합니다. 데이터가 있다면 즉시 반환합니다. (대부분의 요청은 여기서 끝납니다.)
2. 데이터가 없다면 그제서야 ReentrantLock 통해 요청 권한을 얻습니다.
3. 락을 얻기 위해 대기하던 중, 앞선 스레드가 데이터를 조회해서 캐시에 채워넣었을 수 있습니다. 따라서 락을 얻은 직후 다시 한 번 캐시를 확인합니다.
4. 2차 확인에서도 데이터가 없다면, 그 때 DB를 조회하여 결과를 Redis에 저장합니다.
5. 대기하던 다른 스레드들에게 권한을 넘깁니다. 대기하던 스레드들은 이제 3번 단계(2차 확인)에서 캐시 히트를 경험하며 DB 부하를 발생시키지 않게 됩니다.
**이렇게 구현한 이후, 카페인 캐시때와 같은 테스트를 통해 캐싱 이슈 및 성능 재확인을 통해 제대로 동작함을 검증하였습니다. 테스트 결과가 동일하기에 똑같은 이미지는 첨부하지 않았습니다**
오늘은 캐시를 통해 차트 조회 성능을 개선해봤습니다. 캐시를 적용했다는 말 한마디에 얼마나 많은 고민이 있었을지 깨닫는 계기가 되었습니다.
전체적으로 요약하자면,

1. 캐시 도입 전 성능 병목 원인 분석
2. 성능 개선을 위한 로컬 캐시(Caffeine) 도입
3. Thundering herd & Cache Penetration 문제 발생
4. 로컬 캐시는 Late tick 을 반영하지 못하는 문제 발생
5. Redis 글로벌 캐시를 이용한 데이터 정합성 확보
6. Redis Sorted Set 자료구조 사용을 통해, Cold Start 로 인한 성능 저하 방지
7. Mutex Lock 을 통한 Thundering herd 방지
이정도가 될 것 같습니다.
잘못된 부분이나 더 좋은 방법있다면 댓글 부탁드립니다!
'[Spring] - Study > Project - CoinFlow(비트코인 차트)' 카테고리의 다른 글
| [3] 실시간 Tick 데이터 처리 성능 개선: Redis I/O 병목을 Batch 처리로 해결하기 (1) | 2026.03.31 |
|---|---|
| [2] 실시간 Tick 데이터 처리 성능 개선: JSON 기반 처리의 병목을 Binary 전환으로 해결하기 (0) | 2026.03.27 |
| [1] 실시간 Tick 데이터 처리 성능 개선: 캔들 데이터는 어떻게 저장해야할까? (feat. 비동기, 낙관적 락) (0) | 2026.03.19 |
| [Data Flow] 실시간 차트 데이터 흐름도 재설계: 프론트엔드 연산 제거와 완벽한 정합성 보장하기 (0) | 2026.02.28 |
| 초당 수만 건의 틱 데이터, 거래량은 어떻게 집계해야 할까? (BigDecimal vs Long) (1) | 2026.02.24 |