이전 블로그 글인 Data Flow 설계하기: Latency와 Consistency를 고려해보자에서 이어지는 포스팅입니다.
오늘은 Data Flow 재설계를 하게된 배경과 왜 재설계를 하게 되었는지에 대해 자세히 설명해보고자 합니다!
그럼 지금부터 시작합니다~~
[1] 이전 아키텍처(Dual-Path)의 회고: 어떻게 정합성을 맞추려 했는가?
이전 포스팅에서 다루었던 코인플로우의 초기 아키텍처는 Dual-Path Architecture였습니다.
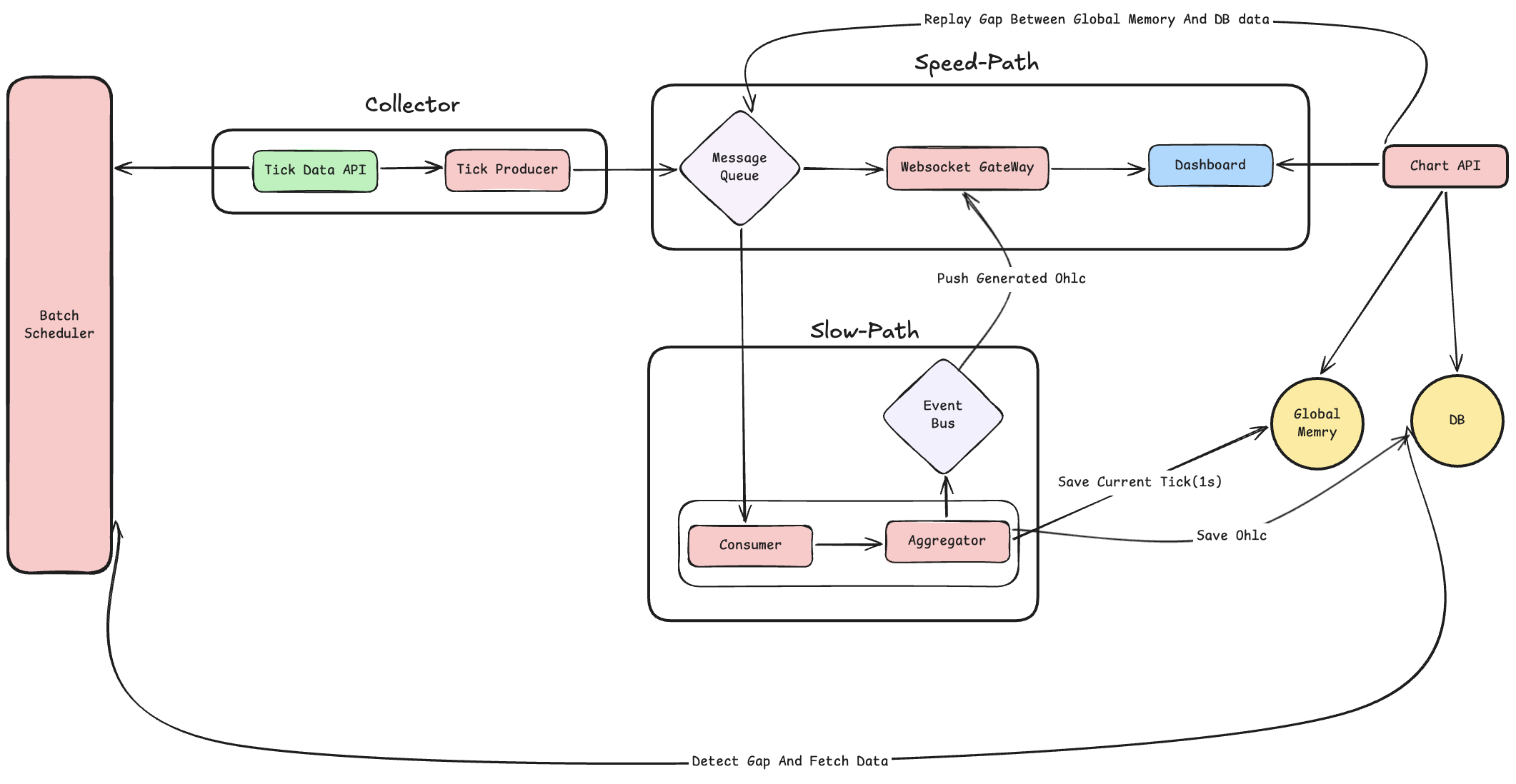
금융 데이터의 생명인 실시간성과 데이터 정합성 모두 잡기 위해, 시스템을 속도 전용 파이프라인(Fast-Path)과 정확도 전용 파이프라인(Slow-Path)으로 완전히 분리했던 구조입니다.
이 구조에서 데이터 정합성을 맞추기 위해 사용했던 핵심 전략 세 가지는 다음과 같습니다.
1. 실시간 틱 전달 (Redis Stream & Fast-Path)
백엔드가 거래소로부터 틱 데이터를 받는 즉시 Redis Stream을 통해 클라이언트(프론트엔드)로 전달합니다. 사용자는 1ms의 딜레이도 없이 체결 내역을 차트에서 확인할 수 있습니다.
2. 프론트엔드 인메모리 집계 (Client-side Aggregation)
클라이언트가 쏟아지는 틱 데이터를 모두 받아 실시간으로 1분봉 캔들을 구성합니다.(백엔드도 같이 집계합니다.)
- 새로 들어온 틱이 현재 고가보다 높으면 갱신(
high = max(high, tick.price)) - 저가보다 낮으면 갱신(
low = min(low, tick.price)) - 거래량 누적(
volume += tick.volume)
이 모든 비즈니스 로직(연산) 책임을 프론트엔드가 짊어지고 있었습니다.
3. 확정 캔들 덮어쓰기 보정 (Event & Snapshot 전략)
네트워크 지연이나 브라우저 성능 이슈로 인해 프론트엔드가 틱을 놓쳐서 스스로 그린 차트 모양이 망가질 수 있었습니다.
이를 방지하기 위해, 백엔드는 1분이 정확히 끝나는 시점에 서버 메모리에서 계산을 완료한 스냅샷(Closed Candle)을 DB에 저장함과 동시에 웹소켓으로 closedEvent를 전달합니다.
프론트엔드는 이 데이터를 받는 순간, 자기가 임시로 그려놨던 부정확한 캔들을 서버가 준 캔들로 갈아 끼워 최종 정합성을 확보했습니다.
4. 중간 접속자를 위한 Redis Stream Replay (리플레이) 전략
프론트엔드가 실시간 캔들을 직접 조립할 때 발생하는 또 다른 문제는 사용자마다 최초로 웹사이트에 접속하는 시점이 다르다는 점이었습니다.
예를 들어 1분봉 캔들(10:00:00 ~ 10:00:59)이 생성 중인데, 사용자 A는 10:00:30에 정확히 접속하여 모든 틱을 누적하며 캔들을 그리고 있고, 사용자 B는 10:00:30.5에 뒤늦게 접속했습니다. 사용자 B는 앞선 0.5초의 틱 데이터를 모르기 때문에, 시가와 고가를 새롭게 그려버려 서버나 다른 사용자와 완전히 다른 차트 모양을 보게 됩니다.
(Replay 의 범위를 좁히기 위해, 백엔드에서 1s 마다 해당 분에 해당하는 snapshot을 redis에 갱신시켜주었습니다.)
이를 해결하기 위해 클라이언트가 최초 접속 시, 백엔드가 Redis Stream에 저장된 해당 분의 과거 틱 데이터를 쫙 긁어서 빠르게 리플레이 해주는 방식을 통해, 중간 접속자도 다른 사람들과 동일한 캔들을 그릴 수 있도록 보정해 주었습니다.
[2] 레거시(Dual-Path) 흐름의 한계와 비즈니스 요구사항의 재정의
Dual-Path 아키텍처는 실시간성 뿐만 아니라, Replay와 Snapshot이라는 온갖 기술을 덧붙여 정합성까지 챙긴 훌륭한(?) 로직이라고 생각했습니다.
하지만 이를 구현하며 여러 한계점들을 직면했습니다. (구현하며 정말 복잡하다고 느꼈고, 여러 오류도 많았습니다 ㅠ)
1. 프론트엔드의 과도한 비즈니스 로직 부담
프론트엔드가 순수하게 UI 렌더링만 담당하는 것이 아니라, 수만 건의 틱 데이터를 받아서 High/Low 값 등을 재계산하는 역할도 가졌습니다.
이로 인해, 리소스 낭비와 프론트엔드 코드의 복잡성이 엄청나게 높아졌습니다..
2. 억지스러운 보정 로직과 순간적인 차트 왜곡
가장 큰 문제는 정합성을 맞추기 위해 서버와 클라이언트 양쪽 파이프라인(Fast, Slow)에 의존해야만 한다는 점이었습니다.
어쨌든 프론트엔드는 1분 마감 정답본(Slow-Path)이 오기 전까지는, 본인이 스스로 계산한 임시 차트를 봐야만 합니다. 만약 일시적인 기기 성능 저하, 네트워크 지연으로 인해 틱 처리가 몇 개라도 밀린다면, 다음 정답 스냅샷이 도착하기 전까지 수십 초 동안 해당 클라이언트는 서버와 완전히 다른, 심각하게 왜곡된 거짓 차트를 보게 됩니다.(클라이언트끼리도 차트가 다를 위험이 존재했습니다.)
프론트엔드 환경에 너무 많은 것을 의존하게 되어버리는 결함이 존재했습니다.
[3] 다시 생각해본 비지니스 요구사항
이쯤 되니 코인 차트 서비스에서의 본질이 무엇인지 다시 생각해보게 되었습니다.
- 현재가는 실시간성이 중요하다. 0.1초의 차이로 매매 타이밍이 달라질 수 있다.
- 하지만 차트는 다르다. 1초 늦게 보든 2초 늦게 보든 상관없다. 중요한 것은 서버와 화면이 100% 동일한 정합성을 보장하는 것이다.
[4] 해결책: 단일 집계 구조 도입
결국 Dual-Path를 과감히 포기하고, Single Aggregator로 모든 흐름을 통합했습니다.
정말 완벽한 정합성을 위해서는 Consumer 모듈에서만 데이터를 집계해야한다고 생각했고, 부가적으로 프론트엔드가 들고 있던 복잡한 캔들 집계 로직을 제거하고자 했습니다.
이 방법의 핵심은 서버 메모리(In-Memory) 상에 존재하는 단 하나의 Aggregator 입니다.
백엔드 앱 하나가 거래소의 모든 틱 데이터를 수신하고, OhlcAccumulator라는 자신의 메모리 공간 위에서 Math.addExact()와 같은 초고속 연산을 통해 초당 수천 번 실시간 캔들을 집계합니다.(여기까지는 이전과 동일합니다.)
그리고 250ms라는 극히 짧은 주기마다, 서버 메모리에서 실시간 캔들 데이터를 그대로 Redis에 덮어쓰고 웹소켓으로 브로드캐스트합니다.
프론트엔드는 이 데이터를 받는 순간, 서버가 이미 완벽하게 계산해둔 캔들스냅샷을 화면에 찍어주기만 하면 끝납니다.
[5] 새로운 구조의 데이터 흐름
새로운 구조는 데이터의 흐름은 직관적이고 SSOT를 만족하여 완벽한 정합성을 보장합니다.
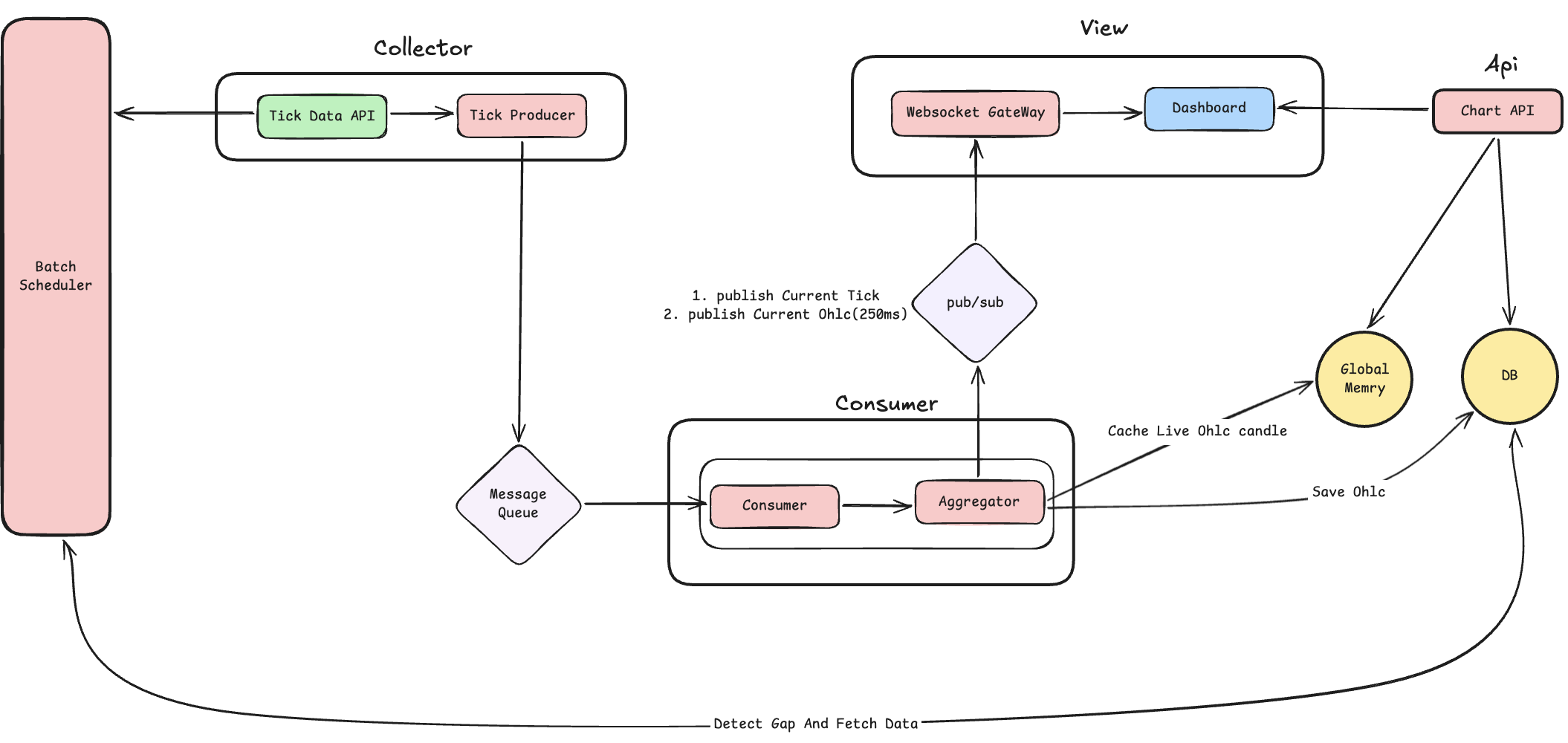
- Collector: 외부 틱 데이터를 발생 즉시 Message Queue(Redis Stream)로 밀어 넣습니다.
- Consumer (Aggregator): Stream에서 틱을 수신하여 내부 캐시 메모리 실시간 OHLC 캔들을 지속적으로 업데이트합니다. (또한, 실시간 데이터를 바로 바로 publish 합니다.)
- Database & Cache: 백엔드는 실시간성 캔들을 250ms(0.25초)마다 Redis에
OpsForValue().set()으로 덮어써버림과 동시에, 웹소켓 pub/sub 에 브로드캐스트 합니다. (캔들이 마감되는 0초에는 DB에 insert 합니다.) - View (Stateless): 웹소켓을 통해 넘어온 서버가 이미 완벽하게 계산해둔 캔들 스냅샷을 프론트엔드는 그저 화면에 찍어주기만 하면 끝납니다. 더하기/빼기는 단 하나도 하지 않습니다.
[6] 결론
이제 코인플로우의 차트는 네트워크가 끊겼다 복구되더라도 아무런 로직이 필요 없습니다.
서버가 250ms마다 무조건 올바른 캔들을 던져주기 때문에, 재연결되는 즉시 다음 스냅샷으로 덮어써지며 서버의 상태와 100% 일치하도록 자동으로 동기화 됩니다.(클라이언트끼리도 같은 화면을 보게 됩니다!)
개발 복잡성(프론트 로직)은 절반으로 줄이고, 정합성은 100%로 끌어올린 설계 변경이었습니다. 코드의 단순함은 설계에서 나온다는 것을 다시금 느끼며 설계의 중요성을 깨닫게 되었습니다.
이번 포스팅에서는 데이터 흐름 설계에 관해 다뤄보았습니다.
어떻게 Tick data를 aggregate 하고, redis 에 저장을 왜 250ms 마다 하는지 등등 구체적인 전략은 앞으로의 포스팅을 통해 소개해드리겠습니다.
잘못된 내용이나 부족한 부분이 있으면 댓글 남겨주시면 감사하겠습니다!
'[Spring] - Study > Project - CoinFlow(비트코인 차트)' 카테고리의 다른 글
| 초당 수만 건의 틱 데이터, 거래량은 어떻게 집계해야 할까? (BigDecimal vs Long) (1) | 2026.02.24 |
|---|---|
| Data Flow 설계하기: Latency와 Consistency를 고려해보자 (0) | 2026.02.20 |
| CoinFlow 프로젝트 시작 ~.~ (0) | 2026.02.13 |